并发编程中的伪共享问题
伪共享(False Sharing)是并发编程中的一种性能问题,它发生在多个线程并发地访问并修改同一缓存行中的不同数据时。
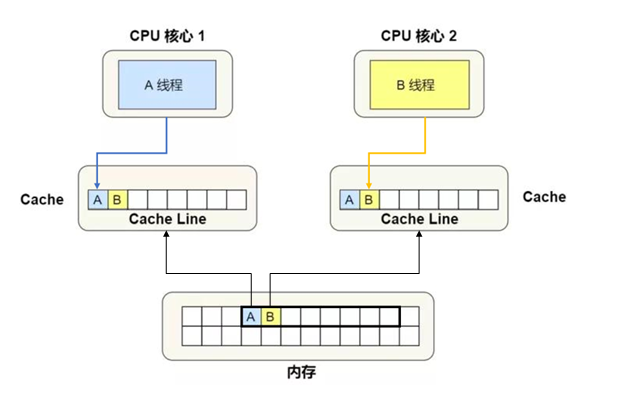
伪共享的产生
计算机内存是按块(通常称为缓存行,cache line)的形式存储和传输的,而不是单个字节或单个变量。这是因为一次性从内存中获取一大块数据(例如64字节)比获取单个字节的效率更高。一旦某个线程需要访问内存中的某个地址,整个缓存行(包含该地址的那一块)就会被加载到该线程的CPU缓存中。
图片引自 :图解丨什么是伪共享?又该怎么避免伪共享的问题?
伪共享的解决方法
根据伪共享产生的原因,避免伪共享一般可以采取以下几种方法:1. 数据填充(Padding):在可能发生伪共享的变量之间添加额外的数据,使它们位于不同的缓存行中。2. 数据对齐(Alignment):确保数据结构的开始地址与缓存行边界对齐,可以减少伪共享的可能性。3. 使用线程本地存储(Thread Local Storage):确保每个线程都有自己的数据副本,从而避免伪共享。
伪共享的方法验证
数据填充
方法1和方法2从本质上来说都是对数据进行填充,尽可能避免共享的数据在同一个缓存行中,从而减少伪共享的可能性。两者都是典型的空间换时间,只不过在实现上略有区别。 这里参考CppReference中的示例代码,实现一种数据填充的方法并进行有效性验证,代码如下:
#include <atomic>
#include <chrono>
#include <cstddef>
#include <iomanip>
#include <iostream>
#include <mutex>
#include <new>
#include <thread>
using namespace std;
using namespace chrono;
std::mutex cout_mutex;
// 最大缓存行字节数
constexpr int MAX_CACHE_LINE_SIZE = 64;
// 无填充
struct AtomWrapper {
std::atomic_uint64_t value;
AtomWrapper() : value(0) {}
AtomWrapper(uint64_t v) : value(v) {}
private:
AtomWrapper(const AtomWrapper &other) = delete;
AtomWrapper &operator=(const AtomWrapper &other) = delete;
};
//有填充
struct AtomWrapperWithPadding {
std::atomic_uint64_t value;
AtomWrapperWithPadding() : value(0) {}
AtomWrapperWithPadding(uint64_t v) : value(v) {}
private:
AtomWrapperWithPadding(const AtomWrapperWithPadding &other) = delete;
AtomWrapperWithPadding &operator=(const AtomWrapperWithPadding &other) = delete;
// padding to max cache line size, 64byte for x86
unsigned char padding[MAX_CACHE_LINE_SIZE - sizeof(std::atomic_uint64_t)] = {};
};
constexpr int max_write_iterations{10'000'000}; // the benchmark time tuning
struct alignas(MAX_CACHE_LINE_SIZE)
OneCacheLiner // occupies one cache line
{
AtomWrapper x{};
AtomWrapper y{};
}
oneCacheLiner;
struct TwoCacheLiner // occupies two cache lines
{
AtomWrapperWithPadding x{};
AtomWrapperWithPadding y{};
}
twoCacheLiner;
inline auto now() noexcept { return std::chrono::high_resolution_clock::now(); }
template<bool xy>
void oneCacheLinerThread()
{
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
oneCacheLiner.x.value.fetch_add(1, std::memory_order_relaxed);
else
oneCacheLiner.y.value.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed { now() - start };
std::lock_guard lk{cout_mutex};
std::cout << "oneCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
oneCacheLiner.x.value = elapsed.count();
else
oneCacheLiner.y.value = elapsed.count();
}
template<bool xy>
void twoCacheLinerThread()
{
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
twoCacheLiner.x.value.fetch_add(1, std::memory_order_relaxed);
else
twoCacheLiner.y.value.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed { now() - start };
std::lock_guard lk{cout_mutex};
std::cout << "twoCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
twoCacheLiner.x.value = elapsed.count();
else
twoCacheLiner.y.value = elapsed.count();
}
int main(void)
{
constexpr int max_runs{4};
int oneCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{oneCacheLinerThread<0>};
std::thread th2{oneCacheLinerThread<1>};
th1.join(); th2.join();
oneCacheLiner_average += oneCacheLiner.x.value + oneCacheLiner.y.value;
}
std::cout << "Average T1 time: "
<< (oneCacheLiner_average / max_runs / 2) << " ms\n\n";
int twoCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{twoCacheLinerThread<0>};
std::thread th2{twoCacheLinerThread<1>};
th1.join(); th2.join();
twoCacheLiner_average += twoCacheLiner.x.value + twoCacheLiner.y.value;
}
std::cout << "Average T2 time: "
<< (twoCacheLiner_average / max_runs / 2) << " ms\n\n"
<< "Ratio T1/T2:~ "
<< 1.0 * oneCacheLiner_average / twoCacheLiner_average << '\n';
return 0;
} 某次的运行结果如下:
oneCacheLinerThread() spent 229.381 ms
oneCacheLinerThread() spent 229.439 ms
oneCacheLinerThread() spent 206.727 ms
oneCacheLinerThread() spent 208.405 ms
oneCacheLinerThread() spent 215.631 ms
oneCacheLinerThread() spent 217.117 ms
oneCacheLinerThread() spent 215.271 ms
oneCacheLinerThread() spent 216.422 ms
Average T1 time: 216 ms
twoCacheLinerThread() spent 18.553 ms
twoCacheLinerThread() spent 19.2109 ms
twoCacheLinerThread() spent 18.489 ms
twoCacheLinerThread() spent 18.965 ms
twoCacheLinerThread() spent 18.6716 ms
twoCacheLinerThread() spent 19.2982 ms
twoCacheLinerThread() spent 18.9782 ms
twoCacheLinerThread() spent 19.0659 ms
Average T2 time: 18 ms
Ratio T1/T2:~ 11.8027数据对齐
数据对齐和填充本质上是一种方法,只不过更高的语法标准提供和更加方便的填充手段(内存对齐)。使用CppReference中给出的一段示例代码验证数据对齐方法的有效性,如下所示:
#include <atomic>
#include <chrono>
#include <cstddef>
#include <iomanip>
#include <iostream>
#include <mutex>
#include <new>
#include <thread>
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 64 bytes on x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │ ...
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
std::mutex cout_mutex;
constexpr int max_write_iterations{10'000'000}; // the benchmark time tuning
struct alignas(hardware_constructive_interference_size)
OneCacheLiner // occupies one cache line
{
std::atomic_uint64_t x{};
std::atomic_uint64_t y{};
}
oneCacheLiner;
struct TwoCacheLiner // occupies two cache lines
{
alignas(hardware_destructive_interference_size) std::atomic_uint64_t x{};
alignas(hardware_destructive_interference_size) std::atomic_uint64_t y{};
}
twoCacheLiner;
inline auto now() noexcept { return std::chrono::high_resolution_clock::now(); }
template<bool xy>
void oneCacheLinerThread()
{
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
oneCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else
oneCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed { now() - start };
std::lock_guard lk{cout_mutex};
std::cout << "oneCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
oneCacheLiner.x = elapsed.count();
else
oneCacheLiner.y = elapsed.count();
}
template<bool xy>
void twoCacheLinerThread()
{
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
twoCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else
twoCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed { now() - start };
std::lock_guard lk{cout_mutex};
std::cout << "twoCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
twoCacheLiner.x = elapsed.count();
else
twoCacheLiner.y = elapsed.count();
}
int main()
{
std::cout << "__cpp_lib_hardware_interference_size "
# ifdef __cpp_lib_hardware_interference_size
"= " << __cpp_lib_hardware_interference_size << '\n';
# else
"is not defined, use " << hardware_destructive_interference_size
<< " as fallback\n";
# endif
std::cout << "hardware_destructive_interference_size == "
<< hardware_destructive_interference_size << '\n'
<< "hardware_constructive_interference_size == "
<< hardware_constructive_interference_size << "\n\n"
<< std::fixed << std::setprecision(2)
<< "sizeof( OneCacheLiner ) == " << sizeof( OneCacheLiner ) << '\n'
<< "sizeof( TwoCacheLiner ) == " << sizeof( TwoCacheLiner ) << "\n\n";
constexpr int max_runs{4};
int oneCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{oneCacheLinerThread<0>};
std::thread th2{oneCacheLinerThread<1>};
th1.join(); th2.join();
oneCacheLiner_average += oneCacheLiner.x + oneCacheLiner.y;
}
std::cout << "Average T1 time: "
<< (oneCacheLiner_average / max_runs / 2) << " ms\n\n";
int twoCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{twoCacheLinerThread<0>};
std::thread th2{twoCacheLinerThread<1>};
th1.join(); th2.join();
twoCacheLiner_average += twoCacheLiner.x + twoCacheLiner.y;
}
std::cout << "Average T2 time: "
<< (twoCacheLiner_average / max_runs / 2) << " ms\n\n"
<< "Ratio T1/T2:~ "
<< 1.0 * oneCacheLiner_average / twoCacheLiner_average << '\n';
} 某次的运行结果如下:
__cpp_lib_hardware_interference_size is not defined, use 64 as fallback
hardware_destructive_interference_size == 64
hardware_constructive_interference_size == 64
sizeof( OneCacheLiner ) == 64
sizeof( TwoCacheLiner ) == 128
oneCacheLinerThread() spent 195.18 ms
oneCacheLinerThread() spent 198.17 ms
oneCacheLinerThread() spent 225.23 ms
oneCacheLinerThread() spent 227.18 ms
oneCacheLinerThread() spent 223.31 ms
oneCacheLinerThread() spent 223.41 ms
oneCacheLinerThread() spent 215.79 ms
oneCacheLinerThread() spent 217.10 ms
Average T1 time: 215 ms
twoCacheLinerThread() spent 19.21 ms
twoCacheLinerThread() spent 19.18 ms
twoCacheLinerThread() spent 19.41 ms
twoCacheLinerThread() spent 19.69 ms
twoCacheLinerThread() spent 19.39 ms
twoCacheLinerThread() spent 19.47 ms
twoCacheLinerThread() spent 19.44 ms
twoCacheLinerThread() spent 20.32 ms
Average T2 time: 19 ms
Ratio T1/T2:~ 11.26 注: hardware_destructive_interference_size和hardware_constructive_interference_size是C++17中新增的宏。
注意事项
本文之所以提供了一种手动填充的方法,原因在于内存对齐的标识符在C++17以下的标准中使用MSVC作为编译器时,如果涉及到动态分配内存,编译器不能保证完全对齐到指定的长度(C++17以下的new操作符没有按照对齐长度分配内存的重载版本)。综上,根据自己的使用场景决定使用手动填充、数据对齐或者在设计上避免共享。









Comments | NOTHING