






g++编译过程学习笔记
学习用例
使用很简单的多文件编译项目,进行编译过程的学习,主要文件构成如下:
.
├── include
│ └── hello.h
└── src
├── hello.cpp
└── main.cpp 其中hello.h声明了一个可以输出Hello World!的函数并在hello.cpp中完成实现。main.cpp中调用hello.cpp,运行时输出相应的内容。
- hello.h
#ifndef HELLO_H_
#define HELLO_H_
void SayHello();
#endif- hello.cpp
#include "hello.h"
#include<iostream>
void SayHello(){
std::cout<<"Hello World!"<<std::endl;
}- main.cpp
#include"hello.h"
int main(){
SayHello();
return 0;
}g++命令及参数介绍
- -g 编译生成带调试信息的可执行文件
g++ -g main.cpp - -O[n] 优化源代码
# -O0 不做优化 # -O1 默认优化 # -O2 除了完成-O1的优化之外,还进行一些额外的调整工作,如指令调整等。 # -O3 则包括循环展开和其他一些与处理特性相关的优化工作。 # 选项将使编译的速度比使用 -O 时慢, 但通常产生的代码执行速度会更快 g++ -O2 main.cpp - -L和-l 指定库文件路径
# -L 后为库文件路径,可以是绝对路径也可以是相对路径 # -l 后紧跟库名,即libmytest.a 掐头(lib)去尾(.a)剩下的名字 g++ -L ../lib/ -lmytest main.cpp - -I 指定头文件搜索路径
g++ -I ../include/ main.cpp - -o 指定输出文件名
g++ main.cpp -o main
编译过程
大多数时候,作为初学者的我们使用IDE或者各种扩展工具来完成cpp文件的编译,此过程中我们习惯性地忽略编译过程。但是,想要学习使用CMake构建大型项目时,如果能够熟悉编译过程,那么就能够很快的学会编写CMakeLists.txt文件。
这篇学习笔记参考了很多优秀的教程和说明,如有兴趣可以参考相关教程1、相关教程2、相关教程3。
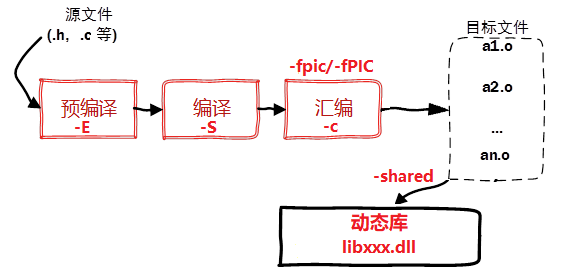
预处理过程(Pre-Proccessing)
预处理阶段:主要完成对包含的头文件和宏定义以及注释等的处理工作,头文件的包含和宏定义其实大多采用直接替换的策略实现的。
在src文件夹下使用以下命令可以实现对源文件的预处理操作,指定生成.ii文件:
g++ -E hello.cpp -I ../include -o hello.ii
g++ -E main.cpp -I ../include -o main.ii可以通过查看.ii文件,了解预处理过程产生的结果。比如,这里展示一下main.ii文件内容如下:
# 1 "main.cpp"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "main.cpp"
# 1 "../include/hello.h" 1
void SayHello();
# 2 "main.cpp" 2
int main(){
SayHello();
return 0;
}编译过程(Compiling)
编译阶段:主要进行语法错误的检查,如果检查无误,则将代码翻译成汇编语言。
在src文件夹下使用以下命令执行编译过程,指定生成.s文件:
g++ -S hello.ii -o hello.s
g++ -S main.ii -o main.s 这一过程将生成汇编代码,不同的机器可能生成的汇编代码有所不同,这里展示一下main.s的文件内容如下:
.file "main.cpp"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
call _Z8SayHellov@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:汇编过程(Assembling)
汇编阶段:主要是将汇编代码生成机器可执行的目标代码,即二进制码,可以发现编辑器已经不能识别和查看二进制文件了。
在src文件夹下使用以下命令执行汇编过程,最后将生成.o文件:
g++ -c hello.s -o hello.o
g++ -c main.s -o main.o链接过程(Linking)
链接阶段:主要将各个.o文件进行链接生成可执行文件,核心工作是解决各个模块之间相互引用的问题。linux系统中生成的可执行文默认为a.out;windows系统中生成的可执行文件后缀为.exe;可以使用-o参数来指定生成的可执行文件名称。
在src文件下使用以下命令生成可执行文件:
g++ main.o hello.o -o main运行可执行文件
运行可执行文件,查看是否正确完成源文件到可执行文件的编译过程:
./main 程序正常运行,并打印了Hello world!,如下图所示:

静态编译和动态编译
编译cpp文件的过程又分为静态编译和动态编译两种。
静态编译是将所有的模块都编译进可执行文件中,当启动可执行文件时,所有的模块都已经具备了,因此具有加载速度快,执行速度快的特点,但是程序体积也会更大,一旦静态库需要更新,程序就需要重新编译,多个程序使用时都需要单独加载,比较浪费内存。
动态编译是将应用程序所需要的模块都编译成动态链接库,当程序启动时,并不会加载所有的模块,只有用到某个模块时才动态的加载使用的模块,多个程序可以使用同一个加载到内容中的动态库,因此Linux中动态库也称为共享库。
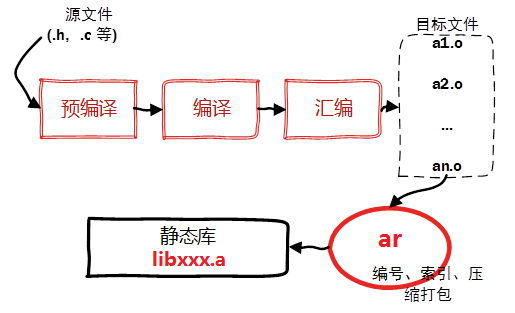
静态库和动态库
静态库
Linux中的静态库由程序ar将.o文件打包生成,目标文件以lib为前缀,以.a作为文件后缀,中间的库名称可以自定义。比如:libhello.a
生成的静态库需要连同相应的头文件发布给使用者,以链接到可执行文件中。


Comments | NOTHING